
Rednotebook 中文词云
rednotebook是个python写的轻量笔记软件,里面有一个Words词云功能比较突出,但不支持中文,每个未被空格分开的句子都会被当成一个单词放入词云中,起不到词云的作用。我找到程序文件位置发现是用python写的,进一步定位到与词云相关的是里面的**data.py中的get_words()函数和gui/clouds.py中的_get_words_for_cloud()**函数,在这两个文件中加入中文分词支持,应该就可以完成想要的词云效果。
选用包:THULAC
https://github.com/thunlp/THULAC-Python
1 | sudo pip install thulac |
前往http://thulac.thunlp.org/message_v1_1填写个人信息之后下载thulac的模型下载完之后发现pip安装的thulac已经自带默认模型,位置在/usr/local/lib/python3.8/dist-packages/thulac/models
装好之后先在python终端试一下:
1 | import thulac |
原因是python3.8不再支持time.clock(),按照报错找到出错的代码,将time.clock()改为time.perf_counter()。修改之后好了
1 | tokenized = thu1.cut(text, text=True) |
用的时候应该text=False(默认情况),返回的是一个二维数组。
进一步测试一下:
1 | text = "小明学习他的离散数学,真是开心啊已经这么晚了" |
其中各个词性的含义:
1 | n/名词 np/人名 ns/地名 ni/机构名 nz/其它专名 |
可见它没法支持英文,意料之中
到时候我们应该只保留词性为n*, v, a,i这几种词性,其他的不显示在词云中。
rednotebook代码魔改
data.py
1 | def is_contain_chinese(check_str): |
gui/clouds.py
1 | def _get_words_for_cloud(self, word_count_dict, ignores, includes): |
其中中文是长度大于等于2的即可纳入词云,英文单词是长度大于4。
最终结果
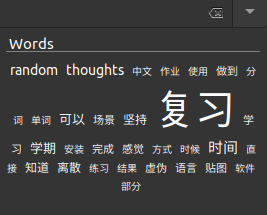
感觉还可以吧?我觉得唯一的缺点就是笔记中的词语很可能不大会重复,而重复多次的词语估计将在这里持续存在很久很久。。。
而且这个thulac模型的加载时间有些长,打开rednotebook要花几秒钟才加载得出词云
- 本文作者: Junetheriver
- 本文链接: http://nicklennonliu.github.io/2021/07/01/Rednotebook 中文词云/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!